writeShort(entry.getName().getBytes(encoding).length); // file name length
这里有个地方需要注意,当文件名是utf8编码格式的时候,需要设置Zip包的通用位标志 (不明白)
第十一个比特为1,代码修改如下:
修改ExtZipEntry类在initEncryptedEntry方法基础上增加一个重载方法:
publicvoidinitEncryptedEntry(booleanutf8Flag) {setCrc(0); // CRC-32 / for encrypted files it's 0 as AES/MAC checks integritiy this.flag |= 1; // bit0 - encryptedif(utf8Flag) {this.flag |=(1<< 11);}// flag |= 8; // bit3 - use data descriptorthis.primaryCompressionMethod = 0x63;byte[] extraBytes = newbyte[11];extraBytes = newbyte[11];// extra data header ID for AES encryption is 0x9901extraBytes[0] = 0x01;extraBytes[1] = (byte)0x99; // data size (currently 7, but subject to possible increase in the// future)extraBytes[2] = 0x07; // data sizeextraBytes[3] = 0x00; // data size// Integer version number specific to the zip vendorextraBytes[4] = 0x02; // version numberextraBytes[5] = 0x00; // version number// 2-character vendor IDextraBytes[6] = 0x41; // vendor idextraBytes[7] = 0x45; // vendor id // AES encryption strength - 1=128, 2=192, 3=256extraBytes[8] = 0x03; // actual compression method - 0x0000==stored (no compression) - 2 bytesextraBytes[9] = (byte) (getMethod() & 0xff);extraBytes[10] = (byte) ((getMethod() & 0xff00) >> 8);setExtra(extraBytes);}
The SHA256 hashing algorithm, like all hashes constructed using the Merkle-Damgård paradigm, is vulnerable to this attack. The length extension attack allows an attacker who knows SHA256(x) to calculate SHA256(x||y) without the knowledge of x. Although it is unclear how length extension attacks may make the Bitcoin protocol susceptible to harm, it is believed that Satoshi Nakamoto decided to play it safe and include the double hashing in his design.
Another explanation [6] for this double hashing is that 128 rounds of SHA256 may remain safe longer if in the far future, a practical pre-image or a partial pre-image attack was found against SHA256.
Bitcoin mining uses the hashcash proof of work function; the hashcash algorithm requires the following parameters: a service string, a nonce, and a counter. In bitcoin the service string is encoded in the block header data structure, and includes a version field, the hash of the previous block, the root hash of the merkle tree of all transactions in the block, the current time, and the difficulty. Bitcoin stores the nonce in the extraNonce field which is part of the coinbase transaction, which is stored as the left most leaf node in the merkle tree (the coinbase is the special first transaction in the block). The counter parameter is small at 32-bits so each time it wraps the extraNonce field must be incremented (or otherwise changed) to avoid repeating work. The basics of the hashcash algorithm are quite easy to understand and it is described in more detail here. When mining bitcoin, the hashcash algorithm repeatedly hashes the block header while incrementing the counter & extraNonce fields. Incrementing the extraNonce field entails recomputing the merkle tree, as the coinbase transaction is the left most leaf node. The block is also occasionally updated as you are working on it.
A block header contains these fields:
Field
Purpose
Updated when…
Size (Bytes)
Version
Block version number
You upgrade the software and it specifies a new version
4
hashPrevBlock
256-bit hash of the previous block header
A new block comes in
32
hashMerkleRoot
256-bit hash based on all of the transactions in the block
A transaction is accepted
32
Time
Current timestamp as seconds since 1970-01-01T00:00 UTC
The body of the block contains the transactions. These are hashed only indirectly through the Merkle root. Because transactions aren’t hashed directly, hashing a block with 1 transaction takes exactly the same amount of effort as hashing a block with 10,000 transactions.
The compact format of target is a special kind of floating-point encoding using 3 bytes mantissa, the leading byte as exponent (where only the 5 lowest bits are used) and its base is 256. Most of these fields will be the same for all users. There might be some minor variation in the timestamps. The nonce will usually be different, but it increases in a strictly linear way. “Nonce” starts at 0 and is incremented for each hash. Whenever Nonce overflows (which it does frequently), the extraNonce portion of the generation transaction is incremented, which changes the Merkle root.
Moreover, it is extremely unlikely for two people to have the same Merkle root because the first transaction in your block is a generation “sent” to one of your unique Bitcoin addresses. Since your block is different from everyone else’s blocks, you are (nearly) guaranteed to produce different hashes. Every hash you calculate has the same chance of winning as every other hash calculated by the network.
Bitcoin uses: SHA256(SHA256(Block_Header)) but you have to be careful about byte-order.
For example, this python code will calculate the hash of the block with the smallest hash as of June 2011, Block 125552. The header is built from the six fields described above, concatenated together as little-endian values in hex notation:
Note that the hash, which is a 256-bit number, has lots of leading zero bytes when stored or printed as a big-endian hexadecimal constant, but it has trailing zero bytes when stored or printed in little-endian. For example, if interpreted as a string and the lowest (or start of) the string address keeps lowest significant byte, it is little-endian.
The output of blockexplorer displays the hash values as big-endian numbers; notation for numbers is usual (leading digits are the most significant digits read from left to right).
For another example, here is a version in plain C without any optimization, threading or error checking.
Here is the same example in plain PHP without any optimization.
<?//This reverses and then swaps every other charfunction SwapOrder($in){
$Split = str_split(strrev($in));
$x='';
for ($i = 0; $i < count($Split); $i+=2) {
$x .= $Split[$i+1].$Split[$i];
}
return $x;
}
//makes the littleEndianfunction littleEndian($value){
return implode (unpack('H*',pack("V*",$value)));
}
$version = littleEndian(1);
$prevBlockHash = SwapOrder('00000000000008a3a41b85b8b29ad444def299fee21793cd8b9e567eab02cd81');
$rootHash = SwapOrder('2b12fcf1b09288fcaff797d71e950e71ae42b91e8bdb2304758dfcffc2b620e3');
$time = littleEndian(1305998791);
$bits = littleEndian(440711666);
$nonce = littleEndian(2504433986);
//concat it all
$header_hex = $version . $prevBlockHash . $rootHash . $time . $bits . $nonce;
//convert from hex to binary
$header_bin = hex2bin($header_hex);
//hash it then convert from hex to binary
$pass1 = hex2bin( hash('sha256', $header_bin ) );
//Hash it for the seconded time
$pass2 = hash('sha256', $pass1);
//fix the order
$FinalHash = SwapOrder($pass2);
echo $FinalHash;
?>
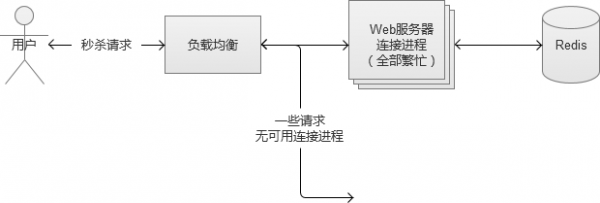
我们通常衡量一个Web系统的吞吐率的指标是QPS(Query Per Second,每秒处理请求数),解决每秒数万次的高并发场景,这个指标非常关键。举个例子,我们假设处理一个业务请求平均响应时间为100ms,同时,系统内有20台Apache的Web服务器,配置MaxClients为500个(表示Apache的最大连接数目)。
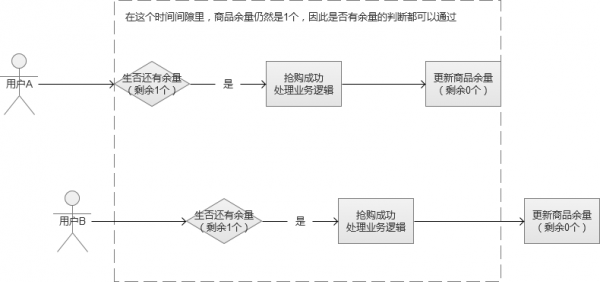
<?php//优化方案1:将库存字段number字段设为unsigned,当库存为0时,因为字段不能为负数,将会返回falseinclude('./mysql.php');$username= 'wang'.rand(0,1000);//生成唯一订单functionbuild_order_no(){returndate('ymd').substr(implode(NULL, array_map('ord', str_split(substr(uniqid(), 7, 13), 1))), 0, 8);}//记录日志functioninsertLog($event,$type=0,$username){global$conn;$sql="insert into ih_log(event,type,usernma)values('$event','$type','$username')";returnmysqli_query($conn,$sql);}functioninsertOrder($order_sn,$user_id,$goods_id,$sku_id,$price,$username,$number){global$conn;$sql="insert into ih_order(order_sn,user_id,goods_id,sku_id,price,username,number)values('$order_sn','$user_id','$goods_id','$sku_id','$price','$username','$number')";returnmysqli_query($conn,$sql);}//模拟下单操作//库存是否大于0$sql="select number from ih_store where goods_id='$goods_id' and sku_id='$sku_id' ";$rs=mysqli_query($conn,$sql);$row= $rs->fetch_assoc();if($row['number']>0){//高并发下会导致超卖if($row['number']<$number){returninsertLog('库存不够',3,$username);}$order_sn=build_order_no();//库存减少$sql="update ih_store set number=number-{$number} where sku_id='$sku_id' and number>0";$store_rs=mysqli_query($conn,$sql);if($store_rs){//生成订单insertOrder($order_sn,$user_id,$goods_id,$sku_id,$price,$username,$number);insertLog('库存减少成功',1,$username);}else{insertLog('库存减少失败',2,$username);}}else{insertLog('库存不够',3,$username);}?>
<?php//优化方案2:使用MySQL的事务,锁住操作的行include('./mysql.php');//生成唯一订单号functionbuild_order_no(){returndate('ymd').substr(implode(NULL, array_map('ord', str_split(substr(uniqid(), 7, 13), 1))), 0, 8);}//记录日志functioninsertLog($event,$type=0){global$conn;$sql="insert into ih_log(event,type)values('$event','$type')";mysqli_query($conn,$sql);}//模拟下单操作//库存是否大于0mysqli_query($conn,"BEGIN"); //开始事务$sql="select number from ih_store where goods_id='$goods_id' and sku_id='$sku_id' FOR UPDATE";//此时这条记录被锁住,其它事务必须等待此次事务提交后才能执行$rs=mysqli_query($conn,$sql);$row=$rs->fetch_assoc();if($row['number']>0){//生成订单$order_sn=build_order_no();$sql="insert into ih_order(order_sn,user_id,goods_id,sku_id,price)values('$order_sn','$user_id','$goods_id','$sku_id','$price')";$order_rs=mysqli_query($conn,$sql);//库存减少$sql="update ih_store set number=number-{$number} where sku_id='$sku_id'";$store_rs=mysqli_query($conn,$sql);if($store_rs){echo'库存减少成功';insertLog('库存减少成功');mysqli_query($conn,"COMMIT");//事务提交即解锁}else{echo'库存减少失败';insertLog('库存减少失败');}}else{echo'库存不够';insertLog('库存不够');mysqli_query($conn,"ROLLBACK");}?>
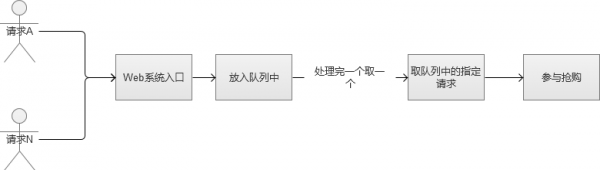
3. FIFO队列思路
那好,那么我们稍微修改一下上面的场景,我们直接将请求放入队列中的,采用FIFO(First Input First Output,先进先出),这样的话,我们就不会导致某些请求永远获取不到锁。看到这里,是不是有点强行将多线程变成单线程的感觉哈。
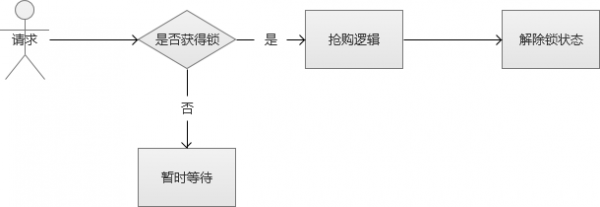
<?php//优化方案4:使用非阻塞的文件排他锁include('./mysql.php');//生成唯一订单号functionbuild_order_no(){returndate('ymd').substr(implode(NULL, array_map('ord', str_split(substr(uniqid(), 7, 13), 1))), 0, 8);}//记录日志functioninsertLog($event,$type=0){global$conn;$sql="insert into ih_log(event,type)values('$event','$type')";mysqli_query($conn,$sql);}$fp= fopen("lock.txt", "w+");if(!flock($fp,LOCK_EX | LOCK_NB)){echo"系统繁忙,请稍后再试";return;}//下单$sql="select number from ih_store where goods_id='$goods_id' and sku_id='$sku_id'";$rs= mysqli_query($conn,$sql);$row= $rs->fetch_assoc();if($row['number']>0){//库存是否大于0//模拟下单操作$order_sn=build_order_no();$sql="insert into ih_order(order_sn,user_id,goods_id,sku_id,price)values('$order_sn','$user_id','$goods_id','$sku_id','$price')";$order_rs= mysqli_query($conn,$sql);//库存减少$sql="update ih_store set number=number-{$number} where sku_id='$sku_id'";$store_rs= mysqli_query($conn,$sql);if($store_rs){echo'库存减少成功';insertLog('库存减少成功');flock($fp,LOCK_UN);//释放锁}else{echo'库存减少失败';insertLog('库存减少失败');}}else{echo'库存不够';insertLog('库存不够');}fclose($fp);?>
namespace app\api\controller\v1; use think\Db; //此处的Db类都以失效,试了多种引入方式都不行 use think\Cache; //同理 use think\Controller; class Curl extends \Thread { public $url; public $result; public function __construct($url) { $this->url = $url; } //线程运行 public function run() { if ($this->url) { $this->result = $this->doshu($this->url);
} } public function doshu($url){ return file_get_contents($url); //所需要访问的网址 } }
我们通常衡量一个Web系统的吞吐率的指标是QPS(Query Per Second,每秒处理请求数),解决每秒数万次的高并发场景,这个指标非常关键。举个例子,我们假设处理一个业务请求平均响应时间为100ms,同时,系统内有20台Apache的Web服务器,配置MaxClients为500个(表示Apache的最大连接数目)。
ALTER TABLE table_name ADD INDEX index_name (column_list)
ALTER TABLE table_name ADD UNIQUE (column_list)
ALTER TABLE table_name ADD PRIMARY KEY (column_list)
其中table_name是要增加索引的表名,column_list指出对哪些列进行索引,多列时各列之间用逗号分隔。索引名index_name可选,缺省时,MySQL将根据第一个索引列赋一个名称。另外,ALTER TABLE允许在单个语句中更改多个表,因此可以在同时创建多个索引。2.CREATE INDEX
CREATE INDEX可对表增加普通索引或UNIQUE索引。
CREATE INDEX index_name ON table_name (column_list)
CREATE UNIQUE INDEX index_name ON table_name (column_list)